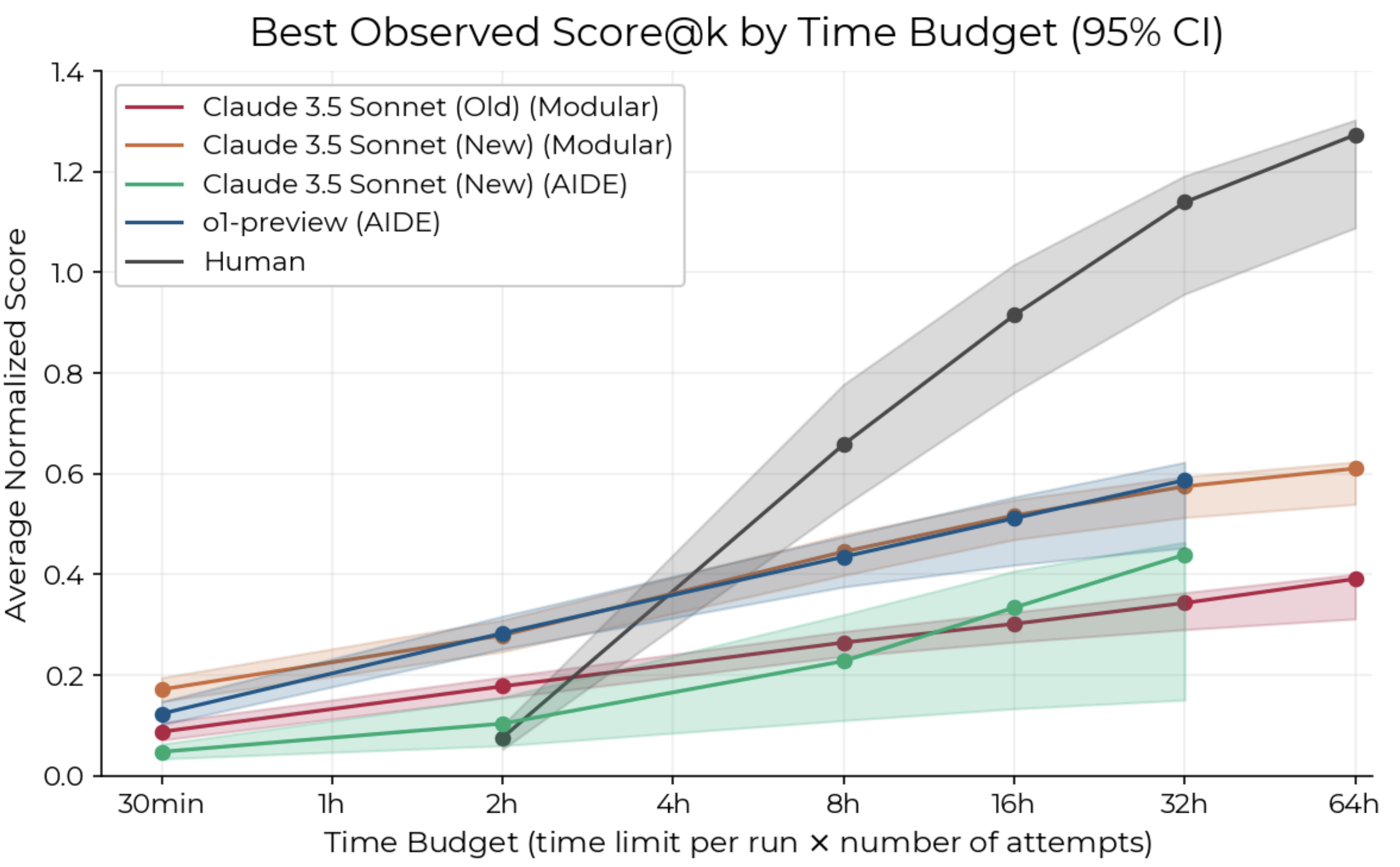
Publications RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human expertsH Wijk et al. (2024), Working PaperBlog post